Aan de Slag met
Datamining[1]
Peter van der Putten (pvdputten@smr.nl)[2]
[3]
Joost Kok (joost@cs.leidenuniv.nl) 2
Samenvatting
Datamining, het ontdekken van relevante kennis in grote hoeveelheden
data, is een strategische bedrijfsactiviteit voor het genereren van klantkennis
en bedrijfswaarde.
Nu de technologie achter datamining langzamerhand
volwassen trekken begint te vertonen, breekt het tijdperk aan van een bredere
toepassing in de praktijk.
Een kritische factor voor succes is een goede inbedding
in de bedrijfsprocessen. In de vorm van cases worden er in dit artikel een
aantal aanknopingspunten gepresenteerd voor mogelijke inzet van datamining bij
de eigen organisatie. Een overkoepelend model voor toepassing en integratie van
datamining projecten sluit het artikel af.
Trefwoorden:
datamining, datawarehousing, database marketing
1 Inleiding
Er is waarschijnlijk nog nooit zoveel geld besteed aan IT als nu. Veel IT-afdelingen van grote organisaties stoppen het leeuwendeel van de capaciteit in belangrijke operationele taken, zoals de invoering van euro en het millenniumprobleem. De keerzijde van de medaille is dat men hierdoor het risico loopt de strategische, geld- en kennisgenerende rol van IT te veronachtzamen. Op deze manier kost IT nog steeds geld in plaats van dat het geld oplevert.
Datamining is een voorbeeld van een IT instrument met een sterk strategische rol, bijvoorbeeld voor marketing toepassingen. In marketing bestaan er twee tegengestelde vormen van communicatie: massa marketing en eén-op-eén marketing. Massamarketing gaat uit van een enkele boodschap die uitgezonden wordt naar alle klanten via media als kranten, tijdschriften en televisie. Zo’n aanpak impliceert een grote verspilling: slechts een klein deel van het publiek zal het product ook werkelijk kopen. Nu de concurrentie sterker wordt en markten gefragmenteerd raken wordt dit probleem van verspilling nog groter. Dit heeft geleid tot een groeiende populariteit van eén-op-eén marketing. Het uiteindelijke doel is een kosten-effectieve dialoog met individuele klanten op gang te brengen. Klanten die complex, ‘onvoorspelbaar’ gedrag vertonen. Binnen database marketing speelt datamining, de continue analyse van klantgegevens, een sleutelrol in de overgang naar meer directe vormen van communicatie.
Het doel van dit artikel is niet zozeer een inleiding te geven in het onderwerp datamining, maar vooral praktische aanknopingspunten te leveren voor mogelijke inzet van datamining bij de eigen organisatie, zowel voor marketing als voor andere toepassingsgebieden als logistiek of personeelszaken. Eerst zullen we datamining beknopt nader definiëren en positioneren ten opzichte van gerelateerde technologieën zoals datawarehousing. De kern van het artikel wordt gevormd door een viertal case beschrijvingen van geslaagde datamining projecten. Het artikel wordt afgesloten met een korte beschrijving van een overkoepelend model voor toepassing en integratie van datamining in organisaties.
2 Data mining in een notendop
Datamining kan worden gedefinieerd als het ontdekken van strategische kennis in grote hoeveelheden gegevens met intelligente patroonherkenningstechnieken. Deze definitie kan nader toegelicht worden door datamining te positioneren ten opzichte van gerelateerde technologieën.
Laten we het voorbeeld nemen van een ijsfabriek. In eerste instantie leverde de IT afdeling maandelijks een rapportage over verkoop en productie aan het management (zie figuur 1). Deze rapportages werden grotendeels gemaakt met geautomatiseerde bevraag en rapporteer gereedschappen. Indien een van de managers een ietwat afwijkende vraag had, moest deze buiten dit gereedschap om door de IT afdeling beantwoord worden. Gezien de lange tijdsduur tussen vraag en antwoord, werd er vaak afgezien van dit soort ‘lastige’ vragen. Een data warehouse bracht verandering in de situatie. De manager kon nu zelf achter de knoppen gaan zitten en de gegevens analyseren. Een voorbeeld: stel, de winst is een stuk lager uitgevallen deze maand. De manager besluit de winst per regio te bekijken. Inderdaad is de winst met name in de regio noordoost ver beneden peil. Vervolgens bedenkt hij de hypothese dat een specifiek ijsje in deze regio slecht loopt en maakt een overzicht van de winst per product in deze regio. Zo graaft hij dieper en dieper om de oorzaak te vinden.
Zulk een aanpak is echter tijdrovend en naarmate het aantal dimensies toeneemt ondoenlijk. Bovendien is de aanpak afhankelijk van de hypothesen – en mogelijke vooroordelen - die geformuleerd moeten worden door de gebruiker.
|
Eindgebruiker, manager,
marketeer |
Datawarehousing |
Datamining |
|
Statisticus, IT-er |
Querying & Reporting |
Klassiek Statistisch Onderzoek |
|
|
Hypotheses Bevestigen |
Verbanden Ontdekken |
Figuur 1: Positionering van datamining ten opzichte van
gerelateerde technologieën.
Datamining probeert een oplossing te vinden voor het probleem. In het geval van de ijsfabriek zal het datamining systeem zoveel mogelijk zelf op zoek gaan naar interessante afwijkende patronen en de relevante resultaten op een begrijpelijke wijze tonen aan de eindgebruiker. Bijvoorbeeld: als mogelijke verklaring voor de lagere winst is er gebleken dat in regio Noord Oost er significant minder vanilleroomijs verkocht is in de ‘SuperStore’ winkels, terwijl het roomijs in de andere regio’s goed liep. Statistiek kan een handig hulpmiddel zijn om deze patronen te vinden, maar dan wel ‘onder de motorkap’. Andere populaire onderdelen onder de datamining motorkap komen uit de kunstmatige intelligentie, luisterend naar exotische namen als neurale netwerken, beslisbomen en evolutionaire algoritmen. Idealiter hoeft een gebruiker niet te weten hoe deze technieken werken, als de resultaten maar geïnterpreteerd kunnen worden.
Statistiek is dus eén van de valide hulpmiddelen, maar datamining is niet gelijk aan statistisch onderzoek. Datamining is meer gericht op eindgebruikers met weinig statistische expertise en is niet gebonden aan de relatief eenvoudige, lineaire statistische technieken.
3 Cases
Om te illustreren wat voor problemen er in de praktijk al aangepakt zijn met datamining, worden er in dit hoofdstuk een aantal cases beschreven van bestaande succesvolle oplossingen. De eerste twee cases komen uit de hoek van de marketing en de verkoop, daarna worden er cases beschreven op het gebied van logistiek en personeelszaken. Met uitzondering van de logistieke case zijn alle projecten uitgevoerd door Sentient Machine Research.
3.1 Case Marketing en Verkoop: Modelleren van Klantgedrag voor een Verzekeraar
De klassieke toepassing van datamining voor direct marketing is responsvoorspelling. Gewoonlijk is het aantal klanten dat positief reageert op een mailing zeer laag (5% of lager). Predictieve modellen kunnen gebouwd worden om prospects te identificeren die mogelijk geïnteresseerd zijn in een aanbod. Historische gegevens over eerdere mailrespons of productbezit worden gebruikt om het model te bouwen. Als zulke informatie niet beschikbaar is, bijvoorbeeld als het gaat om een nieuw product, wordt er een proefmailing uitgevoerd om aan gegevens te komen. Het resulterende model wordt vervolgens gebruikt om klanten te selecteren uit het bestaande klantenbestand of uit klantenbestanden van dataleveranciers.
De bedrijfsdoelstelling van de case in deze paragraaf was om op kosteneffectieve wijze de markt voor een verzekeringsproduct, een caravanpolis, te vergroten. Als datamining doelstelling werd gekozen een voorspellingsmodel te bouwen dat nieuwe klanten kon identificeren onder bestaande klanten van de verzekeraar.
Elke klant werd gekarakteriseerd door een selectie van 95 variabelen. Deze variabelen konden verdeeld worden in 2 groepen. De productgebruik variabelen definieerden de product portofolio van een individuele gebruiker. Dit waren dus interne (bedrijfseigen) variabelen. Er werden ook externe socio-demografische onderzoeksgegevens ingekocht, die op postcode niveau verzameld waren. Alle klanten met dezelfde postcode kregen dezelfde kenmerken toegewezen. Deze kenmerken bevatten gegevens over opleiding, religie, burgerlijke staat, beroep, sociale klasse, huisbezit en inkomen. De selectie van de variabelen die gebruikt werden was gemaakt op basis van domeinkennis en exploratieve data analyse.
Om kansrijke prospects te kunnen selecteren werd er een model gebouwd om de variabele “bezit een caravanpolis” te voorspellen. Een random steekproef, de trainingverzameling, werd getrokken uit het klantenbestand. De trainingverzameling werd gebruikt om een zogenaamd nearest neighbor voorspellingsmodel in te stellen. In een nearest neighbor model wordt het gedrag van een prospect voorspeld aan de hand van het gedrag van de klanten waar de prospect het meest op lijkt. Het relatieve belang (‘gewichten’) van de verschillende variabelen werd berekend door caravanpolisbezitters te vergelijken met overige klanten. Bij de bepaling van de mate van overeenkomst tussen klanten werd rekening gehouden met deze gewichten. De interne variabelen kregen doorgaans een zwaarder gewicht. Dit lag ook voor de hand: toekomstig gedrag laat zich beter voorspellen vanuit historisch gedrag dan vanuit algemene socio-demografische kenmerken.
Het voorspellingsmodel werd getest op een tweede steekproef van klanten, de testverzameling. Het model moet namelijk niet slechts goede resultaten geven op de groep klanten waarmee het is getraind, maar het name goed doen op ‘nieuwe’ klanten. Voor elke testklant werd een responsscore berekend, een getal tussen 0 en 1 die de potentiële interesse in een caravan moest weergeven.


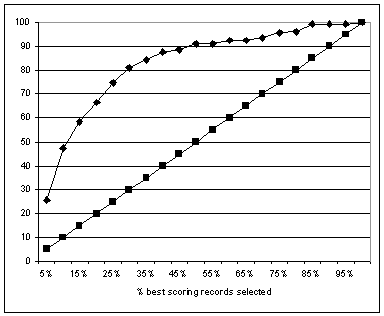
Figuur 2: Responsgrafiek voorspellingsmodel
De kwaliteit van het model werd geëvalueerd aan de hand van de responsgrafiek in figuur 2. Er werden selecties uit de test verzameling gemaakt met variërende grootte (5%, 10%, 15%, enzovoort van het geheel, x-as). De meest kansrijke klanten werden het eerst geselecteerd. Vervolgens werd gemeten welk gedeelte van alle caravanpolis bezitters in de testverzameling was gevonden (y-as). Bijvoorbeeld, indien de top 25% meest kansrijke klanten werd geselecteerd, dan was hiermee al 70% van de caravanpolis bezitters geïdentificeerd. Dit was dus een uitstekend model, bijvoorbeeld om prospects te selecteren voor een mailing. Gezien het feit dat de kosten van een mailstuk gemiddeld op fl. 2,20 liggen, kan het gebruik van een dergelijk model tot forse besparingen leiden.
De voorspelkwaliteit van een model is in het algemeen afhankelijk van de aard van de gegevens (is er wel een verband tussen klantkenmerken en polisbezit?) en de kracht van het gebruikte voorspellingsalgoritme (kan dit algoritme complexe, niet-lineaire verbanden modelleren?).
Responsvoorspelling is met voorsprong de meest populaire toepassing van datamining voor direct marketing. Er zijn echter een groot aantal andere toepassingen denkbaar. Naast het voorspellen van productinteresse werd voor elke verzekerde ook een omzetpotentie berekend. Deze potentie gaf aan welke omzet een klant eigenlijk zou moeten maken, gegeven de omzet van gelijkende klanten. Een andere populaire toepassing is het voorspellen van klantloyaliteit: welke klanten staan op het punt over te stappen naar de concurrent?
3.2 Case Marketing en Verkoop: Schatgraven in Consumentenonderzoeken ten behoeve van advertentieverkoop
Datamining wordt niet alleen gebruikt voor de analyse van klantbestanden, ook markt- en mediaonderzoeken vormen een vruchtbare voedingsbodem. De Telegraaf case is hier een goed voorbeeld van.
De afdeling Marketing Services van de Telegraaf is verantwoordelijk voor marketing van het dagblad De Telegraaf en de tijdschriften van de Telegraaf Tijdschriften Groep (o.a. Autovisie, Elegance, Privé, Man, Hitkrant, Oor), samen goed voor een omzet van enkele honderden miljoenen. Deze afdeling levert adverteerders informatie over doelgroepen en media. Hierbij wordt gebruik gemaakt van de SUMMO onderzoeken, een enorme hoeveelheid gegevens die een beeld geven van life-style, product- en mediagebruik van de Nederlandse consument. De Telegraaf gebruikt als sinds 1994 datamining technieken – profilering en segmentering - om zeer snel relevante informatie over doelgroepen te ontdekken.
Van meer dan
13 duizend personen is zowel een schriftelijke als een telefonische enquête afgenomen. Elke complete enquête
omvat meer dan 2000 vragen en antwoorden. Als een bepaald product of merk
voorkomt in de antwoordenlijst van het
SUMMO (bijvoorbeeld auto=bmw) dan
kan de doelgroep eenvoudig worden geselecteerd.
De standaard
methoden die de Telegraaf voorheen gebruikte boden slechts de mogelijkheid na
te gaan hoe vaak enkele specifieke antwoorden voorkomen in de doelgroep
(bijvoorbeeld: Leest vaak het NRC, of Leeftijd 15-24 jaar). Gezien de enorme
hoeveelheid vragen en antwoorden in de SUMMO onderzoeken leverde deze aanpak
veel praktische problemen op. Het
ontbreekt de medewerkers van de Telegraaf vaak aan de tijd om alle relevante
vragen en antwoorden in het SUMMO te onderzoeken. Bovendien ontberen de
marketeers van de Telegraaf veel voorkennis over de doelgroep in vergelijking
tot de adverteerder. Dus ook al is er tijd in overvloed, dan zal zelfs de meest
ervaren marketeer wel eens een aantal belangrijke, profilerende kenmerken van
een doelgroep over het hoofd kunnen zien. Het was dan ook gewenst dat, in
plaats van de hypothesen van een marketeer te bevestigen, de tool zelf op zoek
ging naar de typische eigenschappen van een doelgroep.
Data mining
profileringstechnieken gebaseerd op statistische toetsen zijn een oplossing
voor het geschetste probleem. Is er een doelgroep geselecteerd, dan wordt er automatisch
een klantprofiel opgesteld van de meest typerende socio-demografische,
lifestyle, consumptie en mediakenmerken van de klant. Hiervoor wordt het gehele
SUMMO onderzoek doorzocht, zodat er geen belangrijke gegevens over het hoofd
worden gezien. Als voorbeeld is in figuur 3 een gedeelte van het
doelgroepprofiel van de 'wodka-drinker' weergegeven.
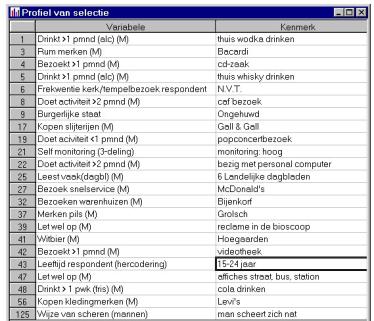
Figuur 3: Gedeelte van het doelgroepprofiel van de
gemiddelde wodkadrinker. Deze kenmerken komen bij de wodkadrinker vaker voor
dan bij de gemiddelde Nederlander.
Het doelgroepprofiel geeft een beeld van de gemiddelde wodkadrinker. De mogelijkheden voor datamining analyse zijn echter nog niet uitgeput. Het is heel wel mogelijk dat de gemiddelde wodkadrinker niet bestaat, maar dat er eerder sprake is van een aantal verschillende deelsegmenten in de doelgroep. De grenzen tussen deze segmenten zijn niet strikt te omschrijven. Elk van de segmenten vraagt om een afzonderlijk communicatieplan. Zo'n gedifferentieerde aanpak kan in een veel hogere effectiviteit resulteren. Met behulp van datamining segmentatie technieken kan men ontdekken om welke deelsegmenten het gaat.
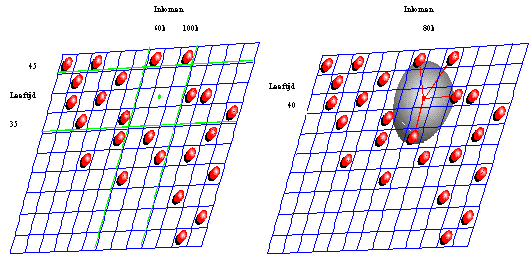
De segmentatie
vindt in een aantal stappen plaats. Eerst worden de wodkadrinkers willekeurig
over een plat vlak verspreid. In een stapsgewijs segmenteerproces worden de
klanten op basis van hun gelijkenis naar elkaar toe getrokken. Het
eindresultaat is een vlak met groepen: binnen een groep lijken klanten zo veel
mogelijk op elkaar, de groepen onderling zijn zo verschillend mogelijk (zie
figuur 4). Deze gelijkenis wordt niet bepaald aan de hand van slechts twee
kenmerken als 'inkomen' en 'leeftijd', maar op basis van alle vragen uit het
SUMMO onderzoek.

Figuur
4: Eindresultaat segmentatie wodkadrinkers. Er kunnen drie verschillende
deelsegmenten aangewezen worden met elk een eigen, specifiek doelgroepprofiel (foto’s ter illustratie).
Profielanalyses
op de deelsegmenten groepen geven een heel andere kijk op de doelgroep dan het
gemiddeld profiel. Er blijken drie duidelijk te onderscheiden segmenten te
bestaan:
·
Een groep kinderen, jongens en meisjes, die wodka drinken
met jus en cola, geïnteresseerd zijn in uitgaan, housemuziek en video’s kijken.
Deze groep leest vrijwel niet, hoogstens bladen als De Telegraaf en de Tros Kompas,
ze letten wel op bioscoop- en buitenreclame en ze kijken veel tv.
·
Een groep twintigers, studenten en starters, die huren en
geïnteresseerd zijn in huisinrichting
en producten gebruiken als Hero, Zwitsal, Libresse, salades, rauwkost en
kattenvoer. Ze lezen relatief vaker de Volkskrant, Viva en VPRO Gids.
·
Een groep zakenmannen van middelbare leeftijd, bezitten
credit card, koopsompolis en hypotheek en rijden vaker in een lease auto. Ze
lezen veel landelijke dagbladen, zoals de Telegraaf en het AD, maar niet de
Volkskrant en tijdschriften zoals de Elsevier en de AVRO-bode. Ze kijken weinig
tv
Duidelijk is
dat uitgaan van een gemiddelde wodka drinker een beperkt beeld oplevert. Voor
positionering van een merk kan deze exercitie een goede aanzet zijn. Communicatie
en eventuele joint-promotions komen beter uit de verf nadat de drie segmenten
onderscheiden zijn.
De Telegraaf
gebruikt datamining vier jaar als centraal instrument voor de
advertentieverkoop van alle Telegraaf titels. Het succes is met name te danken
aan goede inbedding in het bedrijfsproces. Men heeft goed nagedacht waarvoor
datamining specifiek ingezet diende te worden en vervolgens werden er een
aantal marketeers aangesteld en opgeleid voor het maken van analyses. In
navolging van de goede resultaten worden andere nationale onderzoeken nu op
dezelfde wijze geanalyseerd, zoals het CIM in België en het Europese media onderzoek EMS.
3.3 Case Logistiek: Halveer de Voorraad met Efficiënt Voorraadbeheer
Deze case gaat over het voorraadbeheer bij een grote distribiteur in Amerika van medische artikelen. Een uitvoerige beschrijving van deze case kan gevonden worden in het artikel ``Neural Networks Based Forecasting Techniques for Inventory Control Applications’’ (zie literatuurlijst).
Het probleem voor de distribiteur is om de voorraad van elk product te bepalen. De bepalende factor daarbij is de verwachte vraag van klanten op een bepaald moment. Twee conflicterende optimalisatiecriteria spelen een rol: enerzijds moet de totale hoeveelheid artikelen dat op voorraad is zo klein mogelijk gehouden worden, anderzijds wil de distributeur niet dat klanten om een product vragen dat niet op voorraad is. Een manier om dit te kwantificeren is een randvoorwaarde op te leggen met betrekking tot het maximale percentage klanten dat bij een willekeurige winkel niet het product kan kopen dat zij wensen te kopen. Gegeven zo’n randvoorwaarde (bijvoorbeeld vijf procent) moet dan een zo klein mogelijke voorraad gevonden worden.
De methode die tot nu toe gebruikt werd bij de distribiteur was een standaard statistische regressie methode om de vraag voor de komende drie weken te voorspellen. Deze voorspelde vraag werd dan gebruikt als de gewenste voorraad. Elke week werd opnieuw de voorspelde vraag berekend en de voorraad op peil gebracht. Met deze methode was de distribiteur in staat om aan de randvoorwaarde te voldoen.
De vraag is nu of data-mining technieken in staat zijn om op grond van historische gegevens een verbeterde voorspelling te geven zodanig dat de voorraad kleiner gehouden kan worden. Hiervoor is een neuraal netwerk gebruikt dat getraind is op historische data met betrekking tot gerealiseerde verkopen. Het bleek dat de voorspellingen met het neurale netwerk beduidend beter waren dan de regressievoorspellingen: gegeven de randvoorwaarde kon een reductie van 66 procent bereikt worden op het aantal dagen dat een gemiddeld artikel in voorraad gehouden wordt. Hierdoor kan de totale voorraad geneesmiddelen met ongeveer de helft gereduceerd worden.
Deze afname in de aan te houden voorraad vertegenwoordigde een hoeveelheid geneesmiddelen met een waarde van 500 miljoen dollar. Alleen al in rente leverde dit een enorme besparing op voor de distribiteur.
3.4 Case Personeel: Vacature Matching en –Profilering
![]() Matchcare Datacompare is een jong en innovatief bedrijf dat zich
specialiseert in matching en data mining voor e-commerce toepassingen, met name
op de arbeidsmarkt.
Matchcare Datacompare is een jong en innovatief bedrijf dat zich
specialiseert in matching en data mining voor e-commerce toepassingen, met name
op de arbeidsmarkt.
Matchcare beschikt over een database van alle vacatures die recent in dagbladen, tijdschriften en overige print media verschenen zijn. Vacatures worden semi-automatisch gescand en ingevoerd. Van elke vacature worden meer dan 200 variabelen afgeleid zoals functie, beroepsniveau, beroepsgroep, branche en sector gegevens, werksoorten, benodigde vaardigheden, toegestane medische beperkingen, opleidingsvereisten, salaris en secundaire voorwaarden etc. Data mining wordt gebruikt om flexibel te kunnen zoeken naar passende vacatures. Bovendien levert het als meerwaarde de mogelijkheid op om extra marktkennis af te leiden van actuele marktinformatie.
Een gebruiker die wil zoeken in een dergelijke database komt al gauw voor een dilemma te staan. Enerzijds wil men zo precies mogelijk de ideale baan omschrijven; anderzijds wil men de kans verkleinen dat men een interessante alternatieve functie misloopt die niet voor de volle 100% voldoet aan zoekcriteria.
Een data mining techniek als fuzzy matching (ook: nearest neighbor search of case based reasoning) biedt een oplossing voor dit probleem. Gegeven een uitgebreid wensprofiel van kenmerken gaat de datamining tool op zoek naar de 10 (20, 30….) best passende banen (zie figuur 5). Fuzzy matching is wat dit betreft te vergelijken met het zoeken op het internet via AltaVista en het krijgen van suggesties voor alternatieve boeken bij de electronische boekhandel Amazon.com. De gevonden selectie kan weer gebruikt worden om extra informatie af te leiden, zoals een salarisindicatie.
Figuur 5: De werking van matching kan uitgelegd worden
met het volgende voorbeeld (elke stip is een persoon). Stel dat we in een
personeels database op zoek zijn naar vier personen die –idealiter- 40 jaar
zijn en 80.000 gulden verdienen. Als we enkel eisen gebruiken zullen we zelf de
grenzen moeten bepalen waarbinnen gezocht wordt (bijvoorbeeld 35-45 jaar oud,
inkomen 60.000 tot 100.000 gulden). Men moet maar afwachten hoeveel personen er
gevonden worden en aan de hand hiervan de eisen wat betreft leeftijd en inkomen
bijstellen. Selecteren met wensen biedt een oplossing. De wens criteria
beschrijven het ideaal. De matching tool gaat eerst op zoek naar personen die
exact (100%) voldoen. Daarna worden alle criteria tegelijk versoepeld, totdat
het gewenst aantal personen is gevonden.
![]()
Een voorbeeld project op basis van deze data en technologie was een reintegratie project voor gedeeltelijk arbeidsgeschikten, waarbij getracht werd op kosten-effectieve wijze een groot aantal cliënten aan een nieuwe baan te helpen. Gegeven zijn of haar profiel, inclusief medische beperkingen, kreeg een cliënt op regelmatige basis een rapport met de tien meest van toepassing zijnde actuele vacatures. Bovendien werden er met datamining technieken automatische en objectieve analyses gemaakt waarmee de cliënt en de personeelsfunctionaris zicht kreeg op zwakke en sterke punten, scholingsknelpunten, te ontwikkelen vaardigheden etc. Kortom de ‘afstand tot de markt’ van de cliënt werd hiermee in kaart gebracht. Met als voordeel dat de analyse was gebaseerd op het individuele cliëntprofiel en het actuele aanbod in de markt.
Dergelijke matching- en mining technologie kan ook goed ingezet worden voor complexe interne personeelszaken. Hierbij kan onder meer gedacht worden aan job rotation en interne vacaturemarkten, salarisindicatie en functie inschaling, benchmarking en trendanalyse en segmentatie en profilering van groepen functies voor het ontwerpen van nieuwe functieindelingen.
4 Datamining in bedrijf
De cases bieden hopelijk praktische aanknopingspunten voor mogelijke inzet van datamining in het eigen bedrijf. In dit hoofdstuk wordt een model gepresenteerd voor uitvoering van datamining projecten, dat gebruikt kan worden om zelf projecten gestructureerd vorm te geven.
Het einddoel van datamining is te komen tot een lerende organisatie, waarbij het ‘leren’ geen zachte, individuele aangelegenheid is, maar een gecontroleerd, rationeel en efficiënt proces van kennis ontdekken en benutten. Het gaat dan niet meer over een automatiseringstoepassing pur sang, maar over het verbeteren van de core business van het bedrijf.
Het datamining proces in de context van een lerende organisatie laat zich beschrijven met een eenvoudige figuur (zie figuur 6). De binnenste cirkel geeft de stappen in een enkel data mining traject weer.
De buitenste cirkel geeft de context weer waarbinnen data mining plaats vindt. Enerzijds levert data mining nieuwe kennis op en geld. Anderzijds kan geen enkele data mining stap uitgevoerd worden zonder de context – aanwezige kennis en kosten/baten aspecten – in beschouwing te nemen. Het zou onzinnig zijn elk datamining project weer geheel blanco van start te gaan. De kennis vormt de interface naar eerder opgedane kennis en naar die mensen in de organisatie die geen data mining gebruiken, maar wel profijt hebben van de resultaten.
De hamvraag is natuurlijk hoe een dergelijke inzet van datamining praktisch gerealiseerd kan worden. Inbedding in de bedrijfsprocessen, duidelijke gefocuste doelstellingen en acties en een adequate evaluatie van de resultaten vormen de belangrijkste voorwaarden voor succes van een datamining oplossing. Het grootste knelpunt in een datamining project, zowel wat dagenbesteding als doorlooptijd betreft, is de dataverzameling en -preparatie stap. Datawarehousing kan, als ‘geheugen’ van de organisatie, hierbij een belangrijke faciliterende rol spelen. Aan de andere kant kan datamining, als ‘intelligentie’ van de organisatie, zorgdragen voor verdiensten om de investering in het data warehouse te rechtvaardigen. Het moge duidelijk zijn dat in het licht van dit model invoering van datamining niet het installeren van een pakketje of het uitvoeren van een geïsoleerde proefpilot is. Het gaat om het aanzwengelen en in stand houden van het datamining proces als fundamenteel leer- en bedrijfsproces.
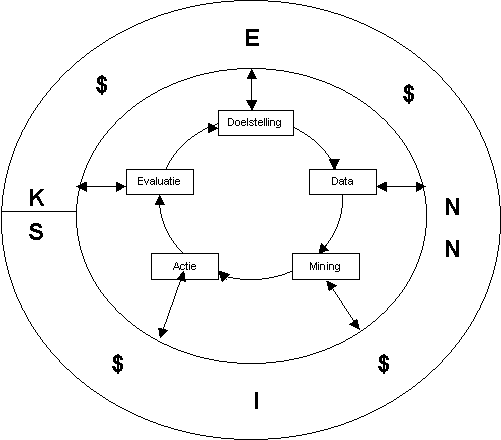
Figuur 6: Het datamining proces
Doelstelling
De doelstelling van het project wordt vastgelegd in termen van
bedrijfsdoelstellingen en meer specifieke data
mining doelstellingen. Bijvoorbeeld: voorspel wie zal reageren op een
direct mailing en genereer een klantprofiel van de top 10% respondenten.
Data
Selecteer de ‘juiste’ data en voer eventueel extra bewerkingen op de data uit.
Indien er geen data warehouse aanwezig is, kan deze stap al gauw 70% van de
tijd in beslag nemen.
Mining
Analyseer de data. Men kan een onderscheid maken tussen predictieve en
descriptieve data mining. In het geval van predictieve data mining is het doel
een (gedrags)voorspelling: voorspel mail respons, abonnement opzegging of omzet
potentieel. Descriptieve ofwel beschrijvende data mining is geschikt om
klantprofielen in kaart te brengen, doelgroepsegmenten te ontdekken enzovoort.
Actie
Onderneem actie op basis van de gevonden analyse resultaten (bij voorbeeld:
zend de 10% prospects met hoogste responskans een maling).
Evaluatie
Evalueer de gevonden resultaten op basis van de data mining criteria en de
bedrijfsdoelstellingen. Ga naar stap 1. Formuleer nieuwe doelstellingen.
5 Conclusie
Datamining bewijst zich steeds vaker in de praktijk als een bruikbaar IT instrument met aantoonbare strategische waarde. De technieken en algoritmen achter datamining vormen niet het meest complexe onderdeel. De crux ligt bij het op- en doorstarten van het datamining proces, om stap voor stap te komen tot een efficiënte, kennisverwervende en dus lerende organisatie. Zodat u als ondernemer kan doen wat het meest telt vandaag de dag: klanten en concurrenten een stap voor zijn.
6 Literatuur
In de Nederlandse vakbladen verschijnen regelmatig artikelen over datamining, met name in de Automatisering Gids, Computable, CustomerBase en Beyond Mapping, Marketing & Data Warehousing (gratis: zie http://geomatrix.net/beyond).
Een uitstekend, zoniet het beste niet-technische boek over de toepassing van datamining is “Data Mining Techniques for Marketing, Sales and Customer Support” van Michael J.A. Berry en Gordon Linoff (John Wiley & Sons, 1997). De Nederlandse branchevereniging voor direct marketing, sales promotion en distance selling (DMSA) heeft een boekje uitgegeven over de toepassing van datamining in een achttal praktijkcases (o.a. bij de VSB, ABN Amro, NS, Centraal Beheer en Readers Digest; zie http://www.dmsa.nl).
Het technisch-wetenschappelijke standaardwerk over data mining is de artikelenbundel “Advances in Knowledge Discovery and Data Mining” van Usama M. Fayyad et al (MIT Press, 1996).
De logistieke case staat beschreven in:
K. Bansal, S. Vadhavkar and A. Gupta. “Neural Network Based Forecasting
Techniques for Inventory Control Applications”. Data Mining and Knowledge
Discovery 2, 97-102 (1998).
De KD Nuggets Website (http://www.kdnuggets.com) is het beste startpunt op het web voor achtergrondinformatie, een gratis elektronische nieuwsbrief en links.
7 Auteursgegevens
Peter van der Putten studeerde cognitieve kunstmatige intelligentie aan de Universiteit Utrecht. Hij werkt nu sinds enige jaren als consultant voor Sentient Machine Research, een data mining bedrijf in Amsterdam. Uitgevers, banken, verzekeraars en de politie behoren tot de klantgroepen die hij adviseert. Daarnaast is hij sinds begin 1998 verbonden aan het Leiden Institute of Advanced Computer Science, alwaar hij onderzoek verricht op het gebied van data mining.
Joost Kok is hoogleraar Algoritmen en Programmeermethodieken aan het het Leiden Institute of Advanced Computer Science. In zijn groep wordt onderzoek verricht naar onder meer neurale netwerken en evolutionaire algoritmen.